

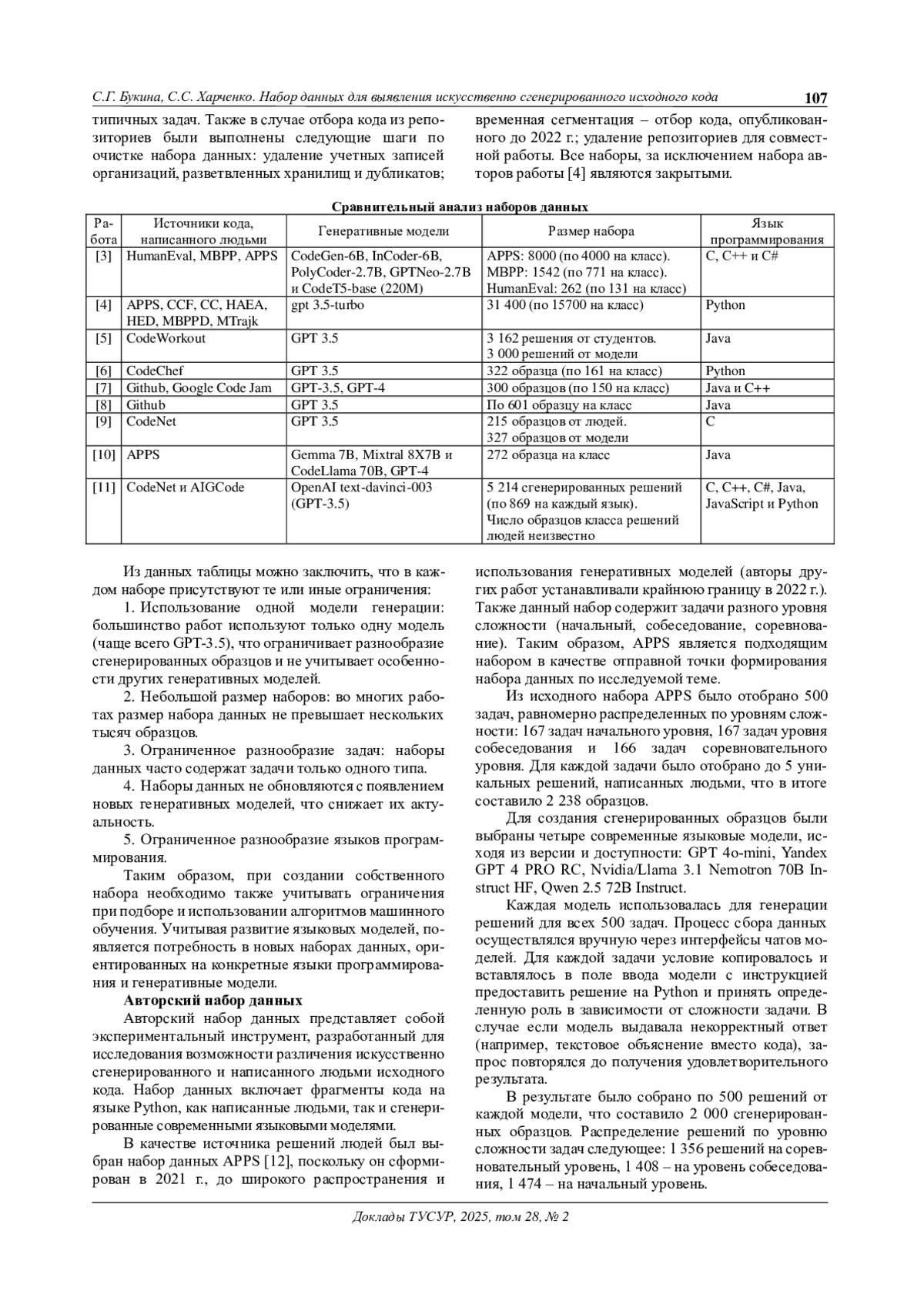
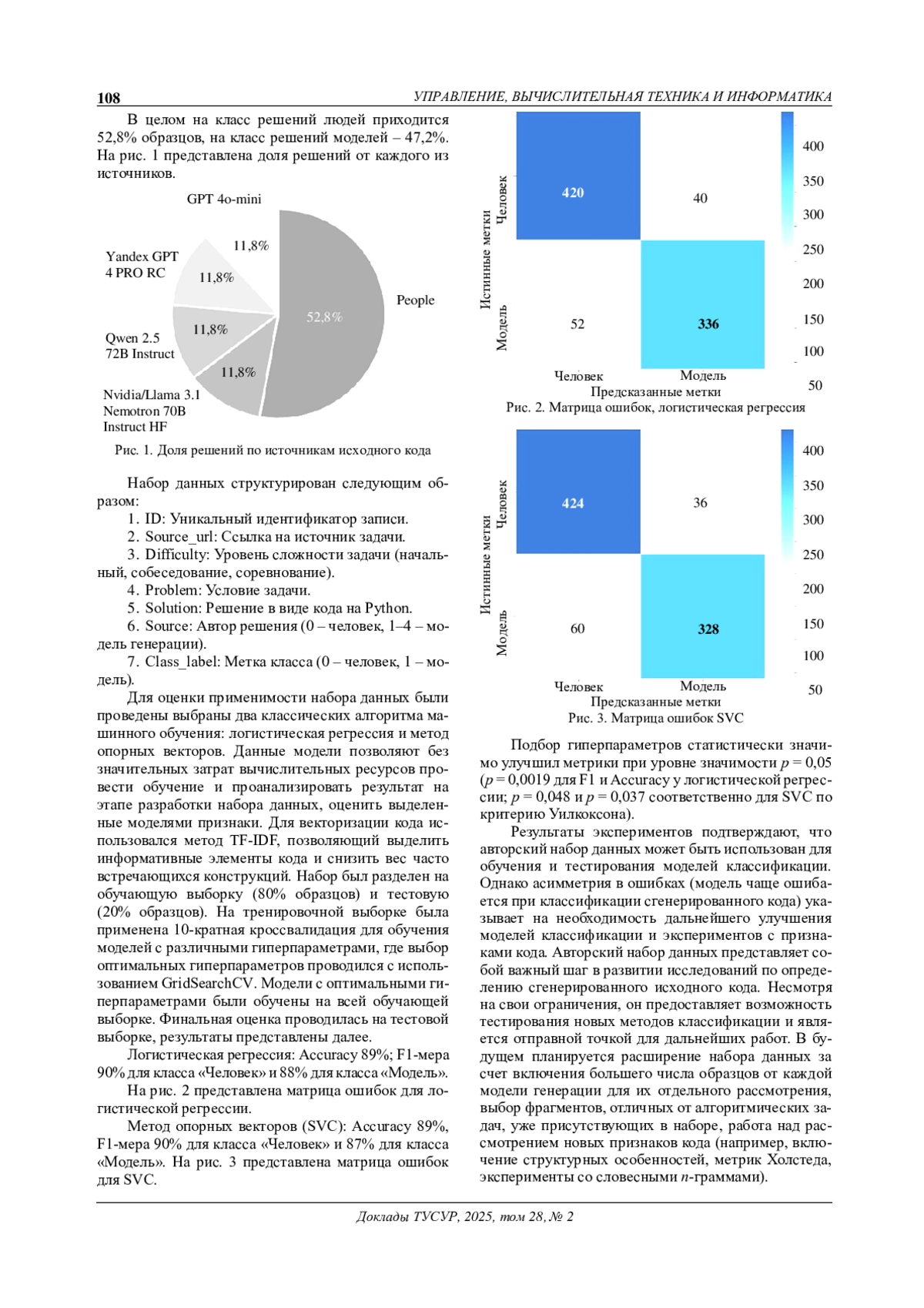
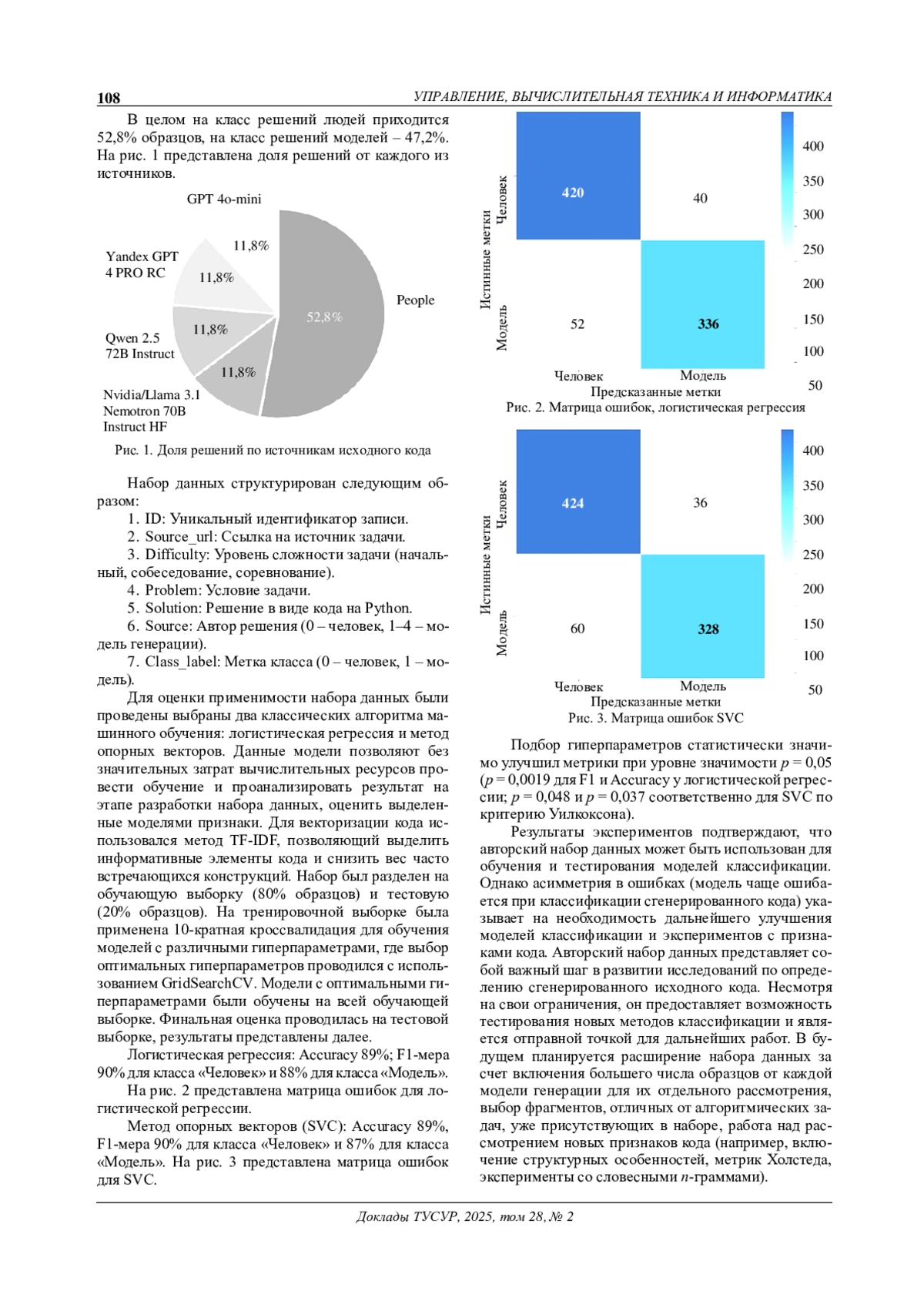
Современные генеративные языковые модели активно используются для автоматической генерации исходного кода, что приводит к необходимости разработки методов его обнаружения. Однако создание наборов данных для определения сгенерированного кода остается затруднительной задачей. В данной работе проводится анализ существующих наборов данных с выявлением их ограничений. Разработан авторский набор данных, включающий решения задач в виде кода на языке программирования Python, написанные людьми и сгенерированные современными языковыми моделями. Проведена экспериментальная оценка с использованием методов машинного обучения. Результаты демонстрируют перспективность предложенного набора, но указывают на необходимость его дальнейшего расширения или же проведения новых экспериментов для подбора наилучшей модели.
Предпросмотр статьи



Идентификаторы и классификаторы
- SCI
- Образование
Современные генеративные модели на основе трансформеров активно используются для автоматической генерации кода, что находит применение в разработке программного обеспечения, тестировании и образовательных задачах.
Если у вас возникли вопросы или появились предложения по содержанию статьи, пожалуйста, направляйте их в рамках данной темы.
Список литературы
1. Hype or not? AI’s benefits for developers explored in the 2023 Developer Survey [Электронный ресурс]. - URL: https://stackoverflow.blog/2023/06/14/hype-or-not-developers-have-something-to-say-about-ai/(дата обращения: 16.09.2024).
2. 024 Developer Survey [Электронный ресурс]. - URL: https://survey.stackoverflow.co/2024/ai/(дата обращения: 16.09.2024).
3. The “Code” of Ethics: A Holistic Audit of AI Code Generators / W. Ma, Y. Song, M. Xue, S. Wen, Y. Xiang // IEEE Transactions on Dependable and Secure Computing. - 2024. - Vol. 21, No. 5. - P. 4997-5013.
4. ChatGPT Code Detection: Techniques for Uncovering the Source of Code / M. Oedingen, R. Denz, R. Engelhardt, M. Hammer // AI Journal. - 2024. - Vol. 5, No. 3. - P. 1066-1094.
5. Detecting ChatGPT-Generated Code Submissions in a CS1 Course Using Machine Learning Models / M. Hoq, Y. Shi, J. Leinonen, D. Babalola // SIGCSE 2024: Proceedings of the 55th ACM Technical Symposium on Computer Science Education. - Portland, Oregon, United States, 2024. - Vol. 1. - P. 526-532.
6. Whodunit: Classifying Code as Human Authored or GPT-4 Generated - A case study on CodeChef problems / O.J. Idialu, N.S. Mathews, R. Maipradit, J.M. Atlee // Proceedings of the 21st International Conference on Mining Software Repositories. - Lisbon, Portugal, 2024. - P. 394-406.
7. Discriminating Human-authored from ChatGPT-Generated Code Via Discernable Feature Analysis / K. Li, S. Hong, C. Fu, Y. Zhang, M. Liu // IEEE 34th International Symposium on Software Reliability Engineering Workshops. - Florence, Italy, 2023. - P. 120-127.
8. GPTSniffer: A CodeBERT-based classifier to detect source code written by ChatGPT / P. Nguyen, J. Rocco, C. Sipio, R.Rubei // Journal of Systems and Software. - 2024. - Vol. 214. - P. 112059. EDN: LXBAKA
9. Bukhari S.A. Issues in Detection of AI-Generated Source Code: The Requirements for the degree of Masters of Science. - Calgary, 2024. - 102 p.
10. Sjoerd S. The Detection of AI Generated Coding Content: The Requirements for the degree of Masters of Science. - Utrecht, 2024. - 75 p.
11. Xu Z. Detecting AI-Generated Code Assignments Using Perplexity of Large Language Models / Z. Xu, V. Sheng // Proceedings of the AAAI Conference on Artificial Intelligence. - Vancouver, Canada, 2024. - P. 23155-23162.
12. Набор данных APPS на платформе Hugging Face [Электронный ресурс]. - URL: https://huggingface.co/datasets/codeparrot/apps (дата обращения: 24.10.2024).
13. Chen M. Evaluating Large Language Models Trained on Code / M. Chen, J. Tworek, H. Jun [Электронный ресурс]. - URL: https://arxiv.org/abs/2107.03374 (дата обращения: 16.02.2025).
14. Allamanis M. A Survey of Machine Learning for Big Code and Naturalness / M. Allamanis, E. Barr, P. Devanbu // ACM Computing Surveys (CSUR). - 2018. - Vol. 51, No. 81. - P. 1-37.
15. Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models / P. Vaithilingam, T. Wu, E. Glassman // Proceedings of the CHI Conference on Human Factors in Computing Systems Extended Abstracts - 2022. - No. 332. - P. 1-7.
Выпуск

Другие статьи выпуска

При эксплуатации литий-ионных аккумуляторов (ЛИА) нередко возникают отказы, что делает задачу прогнозирования их предаварийного состояния актуальной для предотвращения аварийных ситуаций. В данной работе предлагается алгоритм прогнозирования предаварийного состояния ЛИА, основанный на кубической сплайн-интерполяции. С помощью данного метода осуществляется прогнозирование будущего значения напряжения аккумулятора с последующей коррекцией значением, поступающего с датчика напряжения. Результатом работы алгоритма является формирование цифрового «портрета» напряжения аккумулятора в предаварийном режиме, в котором выделяются характерные особенности, интерпретируемые как признаки приближающегося отказа. Эффективность предложенного подхода подтверждена в рамках расчётного примера, где алгоритм применён для выявления предвестников аварийного состояния ЛИА. Полученные результаты показали, что разработанный алгоритм обеспечивает высокую точность выявления признаков предаварийного состояния, позволяя своевременно исключить переход аккумулятора в аварийный режим.

Представлена новая пороговая схема цифровой подписи, объединяющая криптографию на решётках с интерполяционными методами. Схема построена на задаче LWR (Learning With Rounding) и может быть использована для защиты IoT-устройств, где сочетание вычислительной эффективности и квантовой стойкости особенно востребовано. Предложенный подход использует интерполяцию Ньютона, демонстрирующую преимущества перед классической интерполяцией Лагранжа в плане производительности и гибкости при работе с динамическими группами участников.

Рассматривается аппаратная платформа, выполненная в виде учебно-лабораторного стенда, предназначенного для изучения цифровой электроники, программирования микроконтроллеров и программируемых логических интегральных схем, отличительной особенностью которой является замена электрических соединений между базовыми элементами на оптические. Целью создания данной платформы является повышение наглядности изучаемых процессов для обучаемых и снижение вероятности отказа стенда вследствие ошибочных действий обучаемого. Также освещаются принципы, на которых основывается аппаратная платформа, инженерные решения пригодные для создания учебно-лабораторного стенда на её основе, возможная методика работы с аппаратной платформой преподавателей и студентов. Рассматриваются итоги апробации разработанного стенда при проведении лабораторных студенческих работ.

Сложность и ответственность решений, принимаемых при управлении потенциально опасными и рискованными операциями, а также операциями с высокой стоимостью ошибок, часто не позволяют полностью автоматизировать управление высокоразмерными технологическими процессами. В статье представлены проблематика методологии управления, основные положения и этапы методологии прецедентной адаптации контура управления многомерных технологических процессов к изменяющимся условиям их протекания. Приведено описание процедуры нейросетевой адаптации и принципов выбора типа и топологии нейросети, подстраивающей контур управления технологическими установками. Приведены условия оптимальности использования многослойных архитектур нейронных сетей и формулы расчета числа их межнейронных связей и слоев.

Приведены результаты анализа современных открытых технологий и программных средств, используемых для исследования и визуализации сейсмической информации. Для данной сферы характерно наличие в свободном доступе большого объёма разноформатных данных, что позволяет эффективно использовать компьютерные методы их обработки. Для компьютерной обработки сейсмической информации авторами спроектирован и разработан программный комплекс, в составе которого реализованы модули сбора данных из публичных веб-сервисов, их обработки и визуализации с помощью открытых технологий и инструментов для решения ряда задач сейсмического мониторинга. Предложенное решение может быть использовано в качестве составной части информационной системы для управления процессами и информационными потоками организаций, занимающихся сейсмическим мониторингом.

Рассматривается подход к автоматизации диагностики пульмонологических заболеваний с использованием систем поддержки принятия врачебных решений (СППВР) на основе методов нечёткой логики. Проанализированы существующие отечественные и зарубежные решения в данной области, выявлены основные направления развития. Представлены модель пациента и структура системы управления состоянием, а также реализована интеллектуальная система, позволяющая оценивать вероятность диагноза на основании симптомов. В работе применён метод нечёткого логического вывода, обеспечивающий адаптацию моделей к клиническим данным. Проведён анализ значимости симптомов с использованием коэффициентов корреляции Спирмена. Полученные результаты демонстрируют эффективность использования нечёткой логики в задачах медицинской диагностики.

Картирование деревьев является важным типом информации, востребованной в различных областях исследований и практики. Однако решение этой задачи является дорогостоящим и трудоемким процессом, что затрудняет мониторинг обширных территорий. Следовательно, автоматические методы необходимы для оптимизации картографирования деревьев в лесных массивах. Предлагается программный инструмент, в основе которого находится набор изображений крон деревьев, полученных с использованием беспилотных летательных аппаратов (БПЛА), необходимых для обучения нейронных сетей. Основой накапливаемого набора являются кроны деревьев на изображениях RGB с высоким пространственным разрешением (1-10 см). Разработана методика, которая позволяет выравнивать изображения крон деревьев, полученных на разных высотах, которые затем являются основой для формирования набора изображений крон хвойных деревьев. Для подготовки этого набора был применен метод выделения крон каждого дерева в полуавтоматической программе аннотирования изображений. Предлагаемый подход и полученный набор изображений могут быть успешно использованы для обучения нейронных сетей и других подходов машинного обучения, а также методов компьютерного зрения.

Рассмотрены вопросы оценки угроз утечки информации, содержащейся в документах, разрабатываемых в процессе создания информационной системы в защищенном исполнении в интересах проведения ее аттестации на соответствие требованиям о защите информации. Разработаны описательные модели процессов создания такого рода документов. Построены временные диаграммы, иллюстрирующие общее представление этих процессов. Обосновано применение для расчета вероятности их реализации теории потоков и формулы Пуассона. В интересах оценки угроз утечки информации, содержащейся в разрабатываемых документах, приведено общее описание этих угроз, учитывающее не только временной фактор в их реализации, но и особенности процессов разработки документов с применением компьютеров. Разработаны описательные и функциональные модели сценариев реализации угроз утечки информации, содержащейся в разрабатываемых документах, внутренним и внешним нарушителями. Получены аналитические соотношения для расчета вероятностей реализации этих угроз при отсутствии мер защиты. Обоснована возможность повышения защищенности информации, содержащейся в разрабатываемых документах, от утечки за счет применения организационно-технических мер на основе системы охранного мониторинга. Для оценки влияния этих мер, а также защищенности информации от утечки с их применением необходимы соответствующие описательные и функциональные модели, а также показатели и аналитические модели для их расчета, учитывающие фактор времени и логические условия, определяющие динамику реализации исследуемых процессов. Для этого целесообразно использовать аппарат составных сетей Петри-Маркова. Разработанные в статье функциональные модели и построенные временные диаграммы могут быть использованы в качестве основы для применения этого аппарата.

Представлен вариант программного обеспечения, позволяющего оценивать степень удовлетворенности пользователей ответами искусственного интеллекта в тестах биологического, психического и социального уровней. Степень удовлетворенности пользователей оценивается по соответствию их восприятия ответа искусственного интеллекта одному из пяти вариантов оценочных суждений. Получены первые результаты тестирования, показывающие перспективы использования данного программного комплекса.

Доработан функционал приложения с графическим интерфейсом по выработке бинарных последовательностей на облачных квантовых компьютерах в рамках добавления программных инструментов построения регрессионных моделей. Построены модели множественной линейной регрессии и бинарного выбора, где в качестве независимых параметров моделей использованы актуальные на момент эксперимента технические характеристики квантовых состояний. Прогнозируемые значения отражают ожидаемые результаты проверки последовательностей набором статистических тестов NIST STS, а также степень равномерности распределения «0» и «1» в сгенерированных последовательностях. В рамках исследования, основываясь на информации об актуальных технических характеристиках квантового процессора, предложены подходы к прогнозированию результатов генерации случайных чисел на квантовых вычислительных устройствах, что может быть полезным при проектировании квантовой схемы до ее непосредственного запуска.

Приведены описание методики построения нечётких классификаторов данных смешанного типа, их многокритериальная оценка и выбор на основе принципов оптимальности. Методика состоит из следующих основных разделов: 1) трехэтапное построение множества нечётких классификаторов смешанных данных с использованием метаэвристического алгоритма «саранчи»; 2) ранжирование полученных классификаторов по трём критериям: ошибка классификации, количество признаков, количество правил; 3) нормализация рангов; 4) формированные Парето-множества классификаторов; 5) выбор нечёткого классификатора на основе принципов оптимальности.

Применение систем искусственного интеллекта на основе методов машинного обучения в критически важных проблемных областях связано с высокими рисками и требует объяснения человеку полученного результата. Прогностические модели, обладающие таким свойством, называются интерпретируемыми. Отсутствие такой возможности снижает уровень доверия к результату и может быть причиной замедления общественного принятия и внедрения таких систем. Системы искусственного интеллекта на основе нечетких систем позволяют объяснить результат своего решения. Благодаря наличию базы продукционных правил они способны выражать знания в ориентированной на человека форме, используя термины естественного языка. Предложена методика построения нечетких классификаторов, направленная на улучшение интерпретируемости с учетом недостатков известных методов построения. Методика включает в себя применение алгоритмов смешанной многокритериальной оптимизации, дискретной оптимизации, градиентного спуска и метода разделения данных. Проведен эксперимент на 38 общедоступных наборах данных из различных проблемных областей для оценки эффективности классификаторов, построенных с помощью предлагаемой методики. Проведено статистическое сравнение с известными интерпретируемыми классификаторами - генетическими нечеткими системами FARC-HD и деревьями решений CART. Применение методики позволило при сопоставимой точности статистически значимо повысить интерпретируемость классификаторов путем уменьшения числа правил, числа признаков и общего числа нечетких терминов по сравнению с генетическими системами FARC-HD и числа правил и числа условий в правиле по сравнению с классификаторами на основе деревьев решений CART. Достигнутые результаты свидетельствуют о высоком уровне интерпретируемости классификаторов, построенных с помощью предлагаемой методики.

Предложен алгоритм создания эквивалентной модели силового контура AC/DC-преобразователя для анализа эмиссии кондуктивных помех в программе схемотехнического моделирования LTspice с использованием функции быстрого преобразования Фурье. Проведено сравнение уровней моделируемых кондуктивных помех для двух вариантов схем эквивалента сети питания. Рассмотрены особенности измерения параметров трансформатора и компонентов входного и выходного фильтров, а также их описания в модели силового контура импульсного преобразователя. Экспериментально исследована модель обратноходового преобразователя выходной мощностью 100 Вт. Представленная модель позволяет осуществить предварительную оценку уровня кондуктивных помех преобразователя.

Поставлена цель моделирования и анализа характеристик неотражающего фильтра на основе полосковой трехпроводной связанной линии с использованием системы COMSOL Multiphysics. В качестве методов исследования применено численное моделирование с учетом сосредоточенных RLC -элементов и параметров конструкции, таких как толщина диэлектрического слоя и зазор между токонесущими полосками. В результате проведенного моделирования выявлена зависимость частотных характеристик связанной линии от указанных параметров, а также показана возможность усиления электромагнитной связи между полосками за счет введения дополнительной полоски с плавающим потенциалом. Экспериментальные измерения подтвердили полученные результаты и продемонстрировали соответствие моделированным характеристикам. Новизна работы заключается в разработке конструкции фильтра с улучшенными характеристиками за счет оптимизации параметров связанной линии с дополнительной полоской. Теоретическая значимость заключается в расширении знаний о влиянии геометрических параметров на электромагнитные свойства примененных связанных линий. Практическая значимость работы состоит в создании неотражающих фильтров для радиотехнических систем, в которых требуются дополнительные меры уменьшения отражений между каскадами.

Устройства на основе линий передачи (ЛП) часто используют в качестве альтернативы безэховым и реверберационным камерам при оценке эффективности экранирования материалов и кабелей, а также уровней электромагнитной эмиссии и восприимчивости небольших радиоэлектронных средств (РЭС) в области электромагнитной совместимости (ЭМС). Одними из конструктивно сложных устройств на основе ЛП являются ТЕМ-камеры. Они представляют собой замкнутую систему сложной геометрической формы конструкции из металла, в которой распространяются поперечные электромагнитные волны, создающие электромагнитное поле с параметрами, регламентированными стандартами для проведения испытаний на ЭМС. Создание подобных устройств на основе ЛП с заданными параметрами и характеристиками зачастую вызывает трудности. Разработанная в данной работе методика позволила на этапе проектирования за счёт комбинирования нескольких видов компьютерного моделирования и вычисления учесть технологические процессы изготовления сложной формы конструкции волноводов из металла. Методика детально описана на примере создания классической симметричной ТЕМ-камеры для испытания объектов РЭС на ЭМС размером до 20×100×100 мм при | S 11| ≤ -21,2 дБ в диапазоне частот до 2 ГГц. Она апробирована при создании устройств на основе ЛП: полосковая линия, малогабаритная ТЕМ-камера и коаксиальная камера с диапазонами рабочих частот до 3, 5 и 12 ГГц соответственно.

Проводится систематизация и классификация защитных меандровых структур. Они классифицированы по характеру диэлектрического заполнения, геометрии поперечного сечения, топологии и способу комбинирования. Показано, как последовательное усложнение структуры от простых симметричных витков до сложных гибридных систем позволяет наращивать эффективность защиты, достигая ослабления сверхкороткого импульса до 143 раз. Предложены формулы для оценки потенциального числа импульсов на выходе структуры, которые напрямую связаны с ее эффективностью. На основе этого анализа представлены теория разложения и методика синтеза меандровых структур с заданными характеристиками. Для демонстрации методики синтезирована и исследована новая структура с ослаблением сверхкороткого импульса до 17,6 раза, а электростатического разряда - до 2,5 раза. Представлены направления дальнейшего совершенствования меандровых структур.

Представлены результаты оценки эффективности способов уменьшения перекрестных связей в линиях передачи. Для этого на примере пары связанных линий оценены коэффициенты связи (ёмкостной, индуктивной и электромагнитной) и уровень перекрестных помех в пассивном проводнике при увеличении расстояния между ними, нанесении диэлектрического покрытия и введении заземленного проводника между сигнальными проводниками линии. Выявлено, что для протяженных линий эффективным способом является нанесение диэлектрического покрытия, но если протяженность линии мала, эффективным способом является введение в линию заземленного проводника. Дополнительно вычисленные частотные зависимости S -параметров линии подтвердили это.

В условиях динамичной воздушной среды беспроводные системы связи с использованием беспилотных летательных аппаратов (БПЛА) подвержены воздействию изменения атмосферы, что приводит к снижению спектральной эффективности и надежности связи. Для улучшения характеристик системы предлагается использовать комбинацию квазициклического кода с низкой плотностью проверок на чётность (QC-LDPC) и высокоуровневых форматов модуляции, таких как M-QAM. С учётом различных высот полёта БПЛА и влияния затухания проведена оценка системы в канале с замиранием Рэлея. Моделирование показало, что схема с QC-LDPC-кодированием и M-QAM обеспечивает значительное снижение вероятности битовой ошибки (BER) по сравнению с некодированной модуляцией, особенно в условиях сильного замирания. Результаты подтвердили надёжность и применимость предлагаемого подхода для задач связи в режиме реального времени с использованием БПЛА.

Экспериментально исследована акустическая спиновая накачка из антиферромагнетика α-Fe2O3 в нормальный металл (Pt). Показано, что возбуждение акустического резонанса в гематите приводит к спиновой аккумуляции на границе с Pt и формированию зарядовых токов, детектируемых с помощью обратного спинового эффекта Холла (ISHE). Предложена и реализована эквивалентная радиотехническая схема, позволяющая качественно описывать взаимодействие упругих и магнитных подсистем и параметры резонатора.
Статистика статьи
Статистика просмотров за 2026 год.
Издательство
- Издательство
- ТУСУР
- Регион
- Россия, Томск
- Почтовый адрес
- 634050, Томская обл, г Томск, пр-кт Ленина, д 40
- Юр. адрес
- 634050, Томская обл, г Томск, пр-кт Ленина, д 40
- ФИО
- Рулевский Виктор Михайлович (РЕКТОР)
- E-mail адрес
- schkarupo.anastasia@yandex.ru
- Контактный телефон
- +7 (902) 7689232
- Сайт
- https://tusur.ru/ru