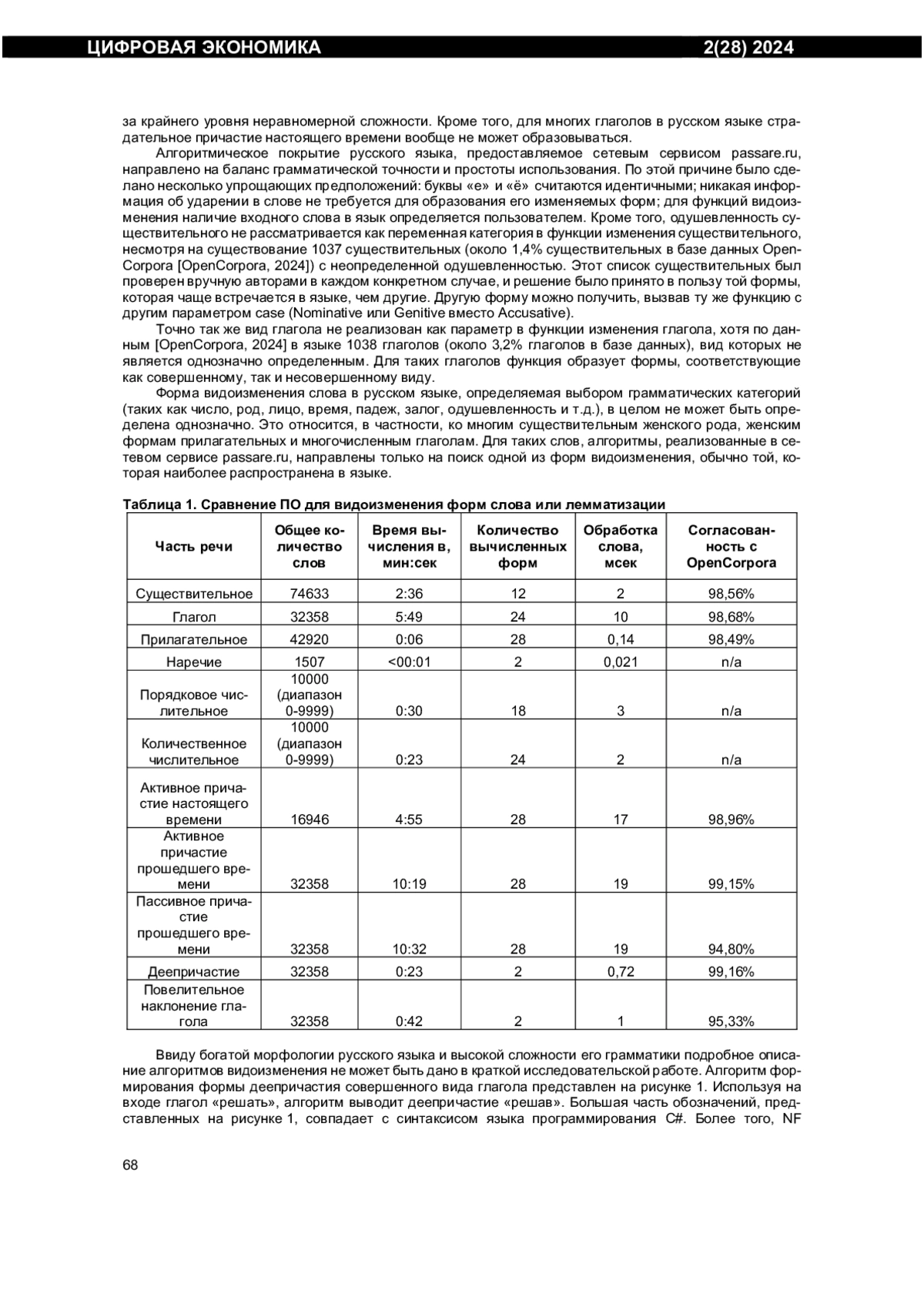
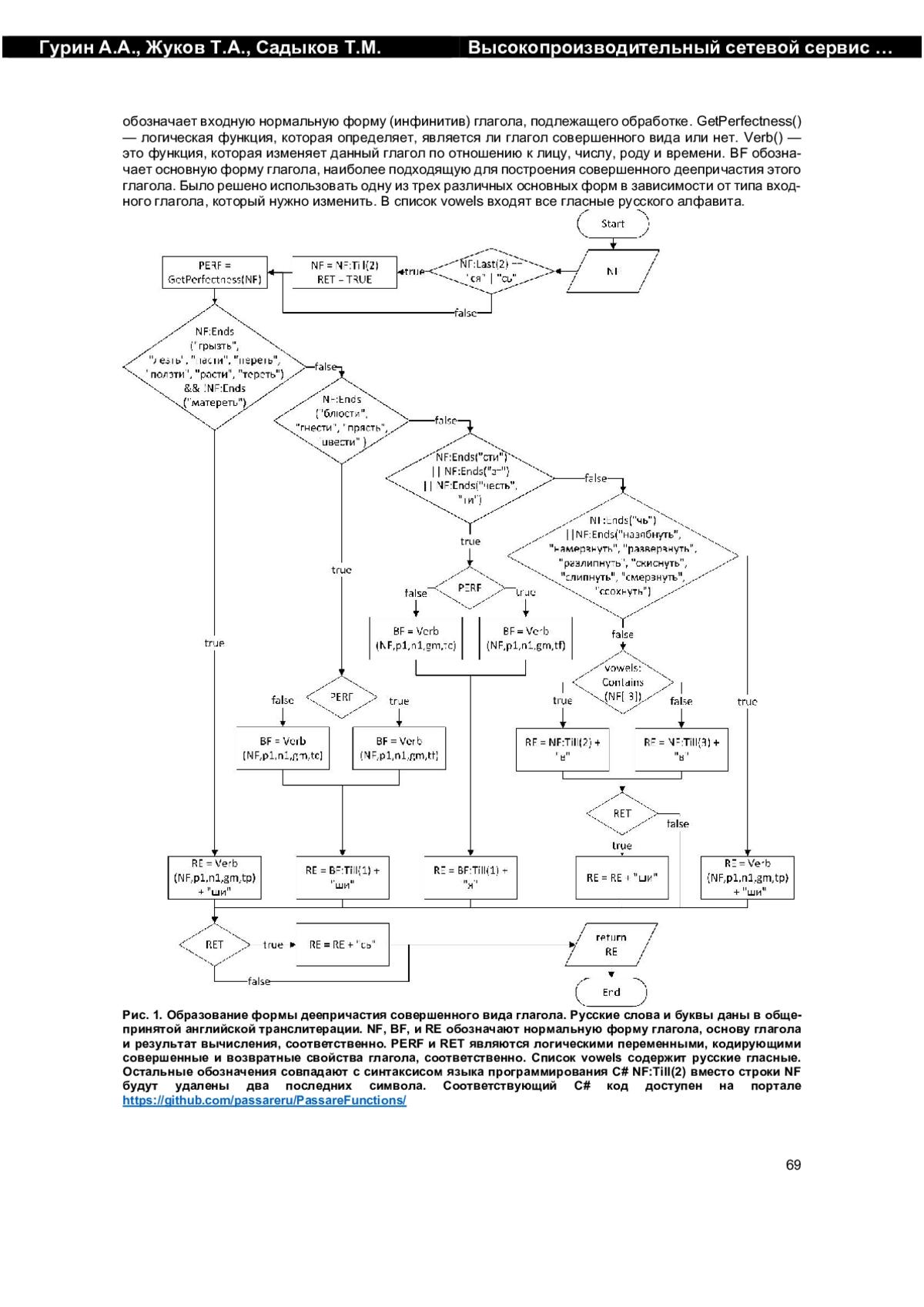
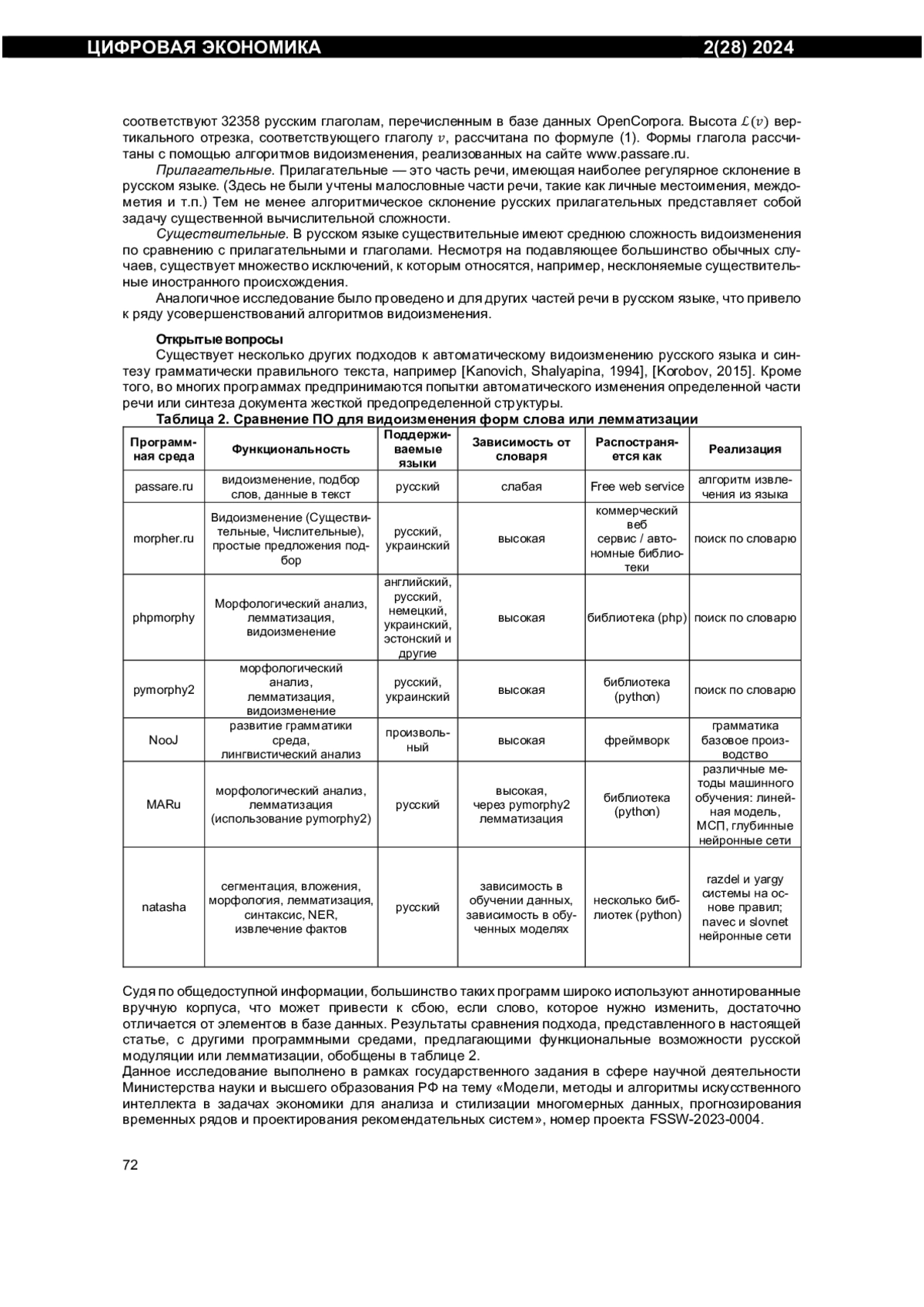
1. Белоногов Г.Г., Котов Р.Г. Автоматизированные информационно-поисковые системы. - М.: Советское радио, 1968. 184 с.
2. Зализняк А. А., “Русское именное словоизменение” с приложением избранных работ по современному русскому языку и общему языкознанию. - М: Наука, 1967. - 752 с.
3. Belonogov, G., Horoshilov, A., Horoshilov, A.: Automation of the English-Russian bilingual phraseological dictionaries based on arrays of bilingual texts. Automatic Documentation and Mathematical Linguistics 44(3), 103-110 (2010).
4. Buddana, H., Kaushik, S., Manogna, P., P.s., S.: Word level lstm and recurrent neural network for automatic text generation. 2021 International Conference on Computer Communication and Informatics, ICCCI 2021 (2021).
5. Cerutti, F., Toniolo, A., Norman, T.: On natural language generation of formal argumentation. CEUR Workshop Proceedings 2528, 15-29 (2019).
6. Chali, Y., Hasan, S.: Towards topic-to-question generation.Computational Linguistics 41(1), 1-20 (2015).
7. Chernikov, B., Karminsky, A.: Specificities of lexicological synthesis of text documents. Procedia Computer Science 31, 431-439 (2014).
8. Conway, D.: An algorithmic approach to English pluralization. In: Second Annual Perl Conference. COPE (2001).
9. Costa, F., Dolog, P., Ouyang, S., Lawlor, A.: Automatic generation of natural language explanations.International Conference on Intelligent User Interfaces, Proceedings IUI (2018).
10. d’Ascoli, S., Coucke, A., Caltagirone, F., Caulier, A., Lelarge, M.: Conditioned text generation with transfer for closed-domain dialogue systems. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics).
11. Faruqui, M., Tsvetkov, Y., Neubig, G., Dyer, C.: Morphological inflection generation using character sequence to sequence learning. CoRR abs/1512.06110 (2015).
12. Foust, W.: Automatic English inflection. In: National Symposium on Machine Translation. pp. 229-233. UCLA (1960).
13. Fuks, H.: Inflection system of a language as a complex network. CoRR abs/1007.1025 (2010).
14. Goldsmith, J.: Unsupervised learning of the morphology of a natural language.Computational Linguistics 27(2), 153-198 (2001).
15. Halle, M., Matushansky, O.: The morphophonology of Russian adjectival inflection. Linguistic Inquiry 37(3), 351-404 (2006).
16. Iomdin, L.: Natural language processing as a source of linguistic knowledge. pp. 68-74 (2003).
17. Kanovich, M., Shalyapina, Z.: The RUMORS system of Russian synthesis. COLING pp. 177-179 (1994).
18. Korobov, M.: Morphological analyzer and generator for Russian and Ukrainian languages.Communications in Computer and Information Science 542, 330-342 (2015). EDN: WRGVPX
19. Levenshtein, V.: Binary codes capable of correcting deletions, insertions and reversals. Soviet Physics Doklady 10(8), 707-710 (feb 1966).
20. OpenCorpora: An open corpus of Russian language, http://www.opencorpora.org/. (2024).
21. Porter, M.: An algorithm for suffix stripping. Program 14(3), 130-137 (1980).
22. Raja, S., Rajitha, V., Lakshmanan, M.: Computational model to generate case-inflected forms of masculine nouns for word search in Sanskrit e-text. J.Comput. Sci. 10(11), 2260-2268 (2014).
23. Segalovich, I.: A fast morphological algorithm with unknown word guessing induced by a dictionary for a web search engine. Proceedings of the International Conference on Machine Learning; Models, Technologies and Applications pp. 273-280 (2003). EDN: PJGYPF
24. Silberztein, M.: Formalizing Natural Languages: The NooJ Approach. John Wiley and Sons Limited (2016).
25. Sorokin, A.: Using longest common subsequence and character models to predict word forms. Proceedings of the 14th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology, SIGMORPHON 2016 at the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016 pp. 54-61 (2016). EDN: RQASZM
26. Streiter, O., Iomdin, L., Sagalova, I.: Learning lessons from bilingual corpora: Benefits for machine translation.International Journal of Corpus Linguistics 5(2), 199-230 (2000). EDN: XFITYZ
27. Subramanian, S., Rajeswar, S., Dutil, F., Pal, C., Courville, A.: Adversarial generation of natural language. Proceedings of the 2nd Workshop on Representation Learning for NLP, Rep4NLP 2017 at the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017 pp. 241-251 (2017).
28. Tran, V.K., Nguyen, L.M., Tojo, S.: Neural-based natural language generation in dialogue using rnn encoder-decoder with semantic aggregation. SIGDIAL 2017 - 18th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Proceedings of the Conference pp. 231-240 (2017).
29. Xiao, T., Zhu, J., Liu, T.: Bagging and boosting statistical machine translation systems. Artificial Intelligence 195, 496-527 (2013).