

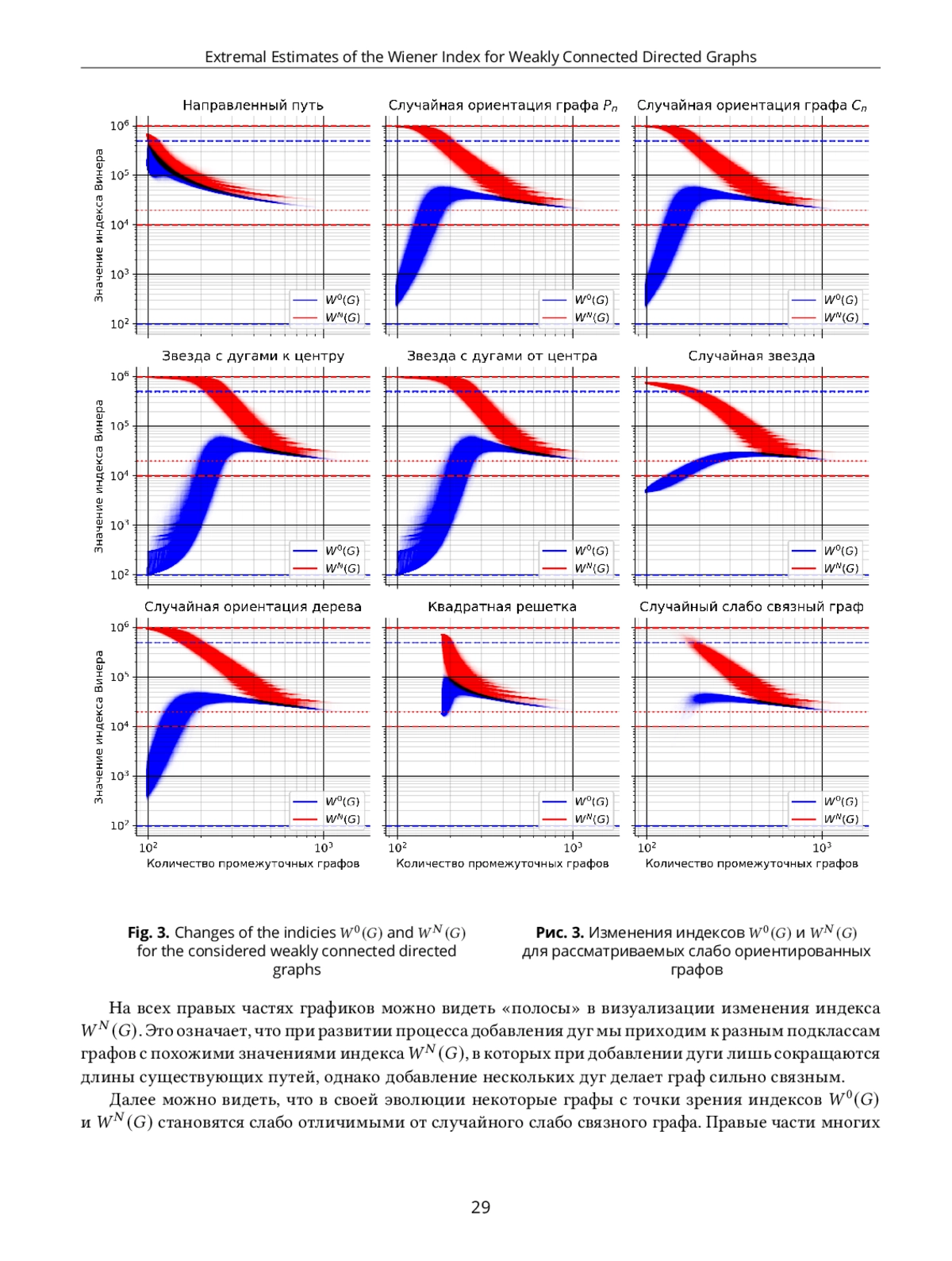
В статье рассматривается индекс Винера для слабо связных ориентированных графов. Для таких графов из-за слабой связности не всегда определено расстояние между вершинами и, что требует уточнения чтобы индекс Винера имел содержательный смысл. Достаточно хорошо изучен случай, когда полагают что при отсутствии пути между вершинами. Мы рассматриваем уточнение, когда равно количеству вершин в графе при отсутствии пути между вершинами и. В статье представлены графы на вершинах, где индекс Винера с таким уточнением достигает минимального и максимального значения. Мы также представляем результаты экспериментов, которые показывают как изменяется индекс Винера (с учетом обоих способов уточнения расстояния) при добавлении дуг в слабо связный ориентированный граф как фиксированной, так и случайной структуры.
Предпросмотр статьи





Идентификаторы и классификаторы
- SCI
- Информатика
Если у вас возникли вопросы или появились предложения по содержанию статьи, пожалуйста, направляйте их в рамках данной темы.






